Our MeiliSearch Experience: Building Fast Search on Low-Memory Servers
July 20, 2025
The reason I used MeiliSearch
Recently, I started working on a new project called Senagg with some friends, and I was responsible for implementing the search feature.
Our environment was hosted on a VPS, and since it’s a Korean-speaking community, we needed to support Korean morphology as well.
Since we were using a VPS, we had to deal with memory limitations.
Our stack already included the frontend, backend, database (MySQL), and a logging system built with Vector, Clickhouse, and Grafana.
Because of that, the system was already using most of the available memory, and we couldn’t afford to add any additional services.

So we started to consider better options for search functionality.
-
Switching from MySQL to PostgreSQL for internal database
We were originally using MySQL as our main database, but we considered switching to PostgreSQL to improve search capabilities.
Although MySQL does support Full-Text Search, it lacks proper indexing and ranking features, which made it less suitable for our needs.
On the other hand, PostgreSQL offers GIN indexing and ranking support, and since I had experience using it in previous projects, it seemed like a strong candidate. -
Implementing MeiliSearch
We also considered using MeiliSearch, which is a modern search stack that is easy to integrate and supports Korean out of the box.
However, since we’re currently hosting everything on a limited VPS environment, memory constraints made it difficult to adopt MeiliSearch right away.
Despite the challenges, we believe MeiliSearch offers an excellent search experience, and it’s definitely something we’d like to use in the future.
So we decided to go with option 2, which is MeiliSearch.
However, as I mentioned earlier, we didn’t have enough memory to implement it properly, so we decided to remove the logging stack to free up resources.
However, since error monitoring is critical, we made the following changes:
- Instead of relying on Grafana alerts, we now send error messages directly from the Spring Boot server.
- We manually check logs using commands like tail by directly accessing our VPS environment.
- We manage basic logging with Logback’s rolling policy, retaining logs for up to 30 days.
- Previously, logs were stored in ClickHouse and automatically deleted every 3 days.
As a result of these changes, we were able to free up a significant amount of memory previously consumed by the logging stack, which allowed us to introduce MeiliSearch.
Q: Why didn’t you choose a more popular stack like Elasticsearch?
Elasticsearch is built with Java and typically consumes around 2–4 GB of memory, which we found to be too heavy for our server environment.
Since minimizing memory usage was a key requirement for us, we chose MeiliSearch instead, which only requires around 500 MB.
Design
In MeiliSearch, an index is like a table in a database where data is stored.
We needed to create this, and after some discussion, we decided to use a unified index that included all types of data.
To support filtering, we added a type field to each document so searches could be narrowed down by type.
So we designed the document structure as follows:
- id: Uniquely generated using "type:index". If a duplicate is inserted, it will be overwritten.
- type: The actual data type, such as "hero".
- title: Main field, given the highest search score.
- description: Sub field. All searchable data except the title goes here.
- url: Redirect URL.
- createdAt: Timestamp for creation.
Working process
We implemented MeiliSearch using Docker and referred to MeiliSearch’s official website for guidance.
Docker
We used Docker Compose, and the configuration file is as follows:
services:
meilisearch:
image: getmeili/meilisearch:v1.15
container_name: meilisearch
environment:
- MEILI_MASTER_KEY=<secret key>
ports:
- "7700:7700"
volumes:
- ./meili_data:/meili_data
restart: unless-stoppedCreate Index
Now we need to create the index.
In my case, I accessed the Docker container directly and ran the command inside it.
docker exec -it meilisearch /bin/bashThe next step was to create and run an init_meilisearch.sh script.
However, you can also run the commands directly using curl.
#!/bin/bash
# configuration
MEILI_URL=http://localhost:7700
MEILI_API_KEY=your_api_key_here
# 1. create the index
curl -X POST "$MEILI_URL/indexes" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $MEILI_API_KEY" \
--data '{
"uid": "contents",
"primaryKey": "id"
}'
# 2. configure the filterableAttributes
curl -X PATCH "$MEILI_URL/indexes/contents/settings/filterable-attributes" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $MEILI_API_KEY" \
--data '["type"]'
# 3. configure the searchableAttributes
curl -X PATCH "$MEILI_URL/indexes/contents/settings/searchable-attributes" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $MEILI_API_KEY" \
--data '["title", "description"]'
echo "✅ Complete MeiliSearch init!"- Creating an index is like creating a table in a traditional database to store data.
- In MeiliSearch, we need to set up filters in advance.
- When performing a search, MeiliSearch uses these filters to determine which data to look through.
Working with Codebase
I added a Handler layer to separate responsibilities as follows:
Controller -> Handler -> Service -> Repository.
This was necessary because we needed to add MeiliSearchService, and calling one service from another would break consistency.
By introducing a Handler, we can coordinate calls to multiple services in a clean and consistent way.
Gradle
We added the following dependency to our Gradle setup:
Reference) https://github.com/meilisearch/meilisearch-java
implementation 'com.meilisearch.sdk:meilisearch-java:0.15.0'Common Class
We created a class to use the official library as follows.
@Configuration
@Profile("!test")
public class MeiliSearchConfig {
@Value("${meilisearch.apiKey}")
private String meiliApiKey;
@Value("${meilisearch.host}")
private String meiliHost;
@Bean
public Client meiliSearchClient() {
return new Client(
new Config(meiliHost, meiliApiKey)
);
}
}You should set up the configuration in application.yml.
Based on the structure we defined earlier, we created a common class to eliminate type errors.
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class SearchDocument {
private String id;
private String type;
private String title;
private String description;
private String url;
private String createdAt;
}MeiliSearchService
Next, we implemented the MeiliSearchService, which handles all core functionalities related to MeiliSearch.
@Service
@RequiredArgsConstructor
public class MeiliSearchService {
private final Client meiliClient;
private final ObjectMapper objectMapper;
public TaskInfo addOrUpdateDocument(SearchDocument document) {
try {
Index index = meiliClient.index("contents");
String json = objectMapper.writeValueAsString(List.of(document));
return index.addDocuments(json);
} catch (Exception e) {
throw new RuntimeException("Failed to add/update document", e);
}
}
public TaskInfo deleteDocument(String id) {
try {
Index index = meiliClient.index("contents");
return index.deleteDocument(id);
} catch (Exception e) {
throw new RuntimeException("Failed to delete document", e);
}
}
public SearchResultPaginated search(String query, String type, int page, int hitsPerPage) {
Searchable result = meiliClient.index("contents")
.search(new SearchRequest(query)
.setPage(page)
.setHitsPerPage(hitsPerPage)
.setFilter(new String[]{"type=\"" + type + "\""})
);
if (result instanceof SearchResultPaginated paginated) {
return paginated;
}
throw new IllegalStateException("Expected paginated search result, but got: " + result.getClass().getSimpleName());
}
public SearchResultPaginated search(String query, int page, int hitsPerPage) {
Searchable result = meiliClient.index("contents")
.search(new SearchRequest(query)
.setPage(page)
.setHitsPerPage(hitsPerPage)
);
if (result instanceof SearchResultPaginated paginated) {
return paginated;
}
throw new IllegalStateException("Expected paginated search result, but got: " + result.getClass().getSimpleName());
}
public TaskInfo removeByType(String type) {
String filter = String.format("type = '%s'", type);
return meiliClient.index("contents").deleteDocumentsByFilter(filter);
}
public void waitForTask(TaskInfo taskInfo) throws InterruptedException {
int taskUid = taskInfo.getTaskUid();
while (true) {
Task task = meiliClient.getTask(taskUid);
String taskStatus = task.getStatus().taskStatus;
System.out.println(taskStatus);
if ("succeeded".equals(taskStatus)) {
break;
} else if ("failed".equals(taskStatus)) {
throw new RuntimeException("Meilisearch task failed: " + task);
}
Thread.sleep(200); // 200ms polling
}
}
}This service includes basic CRUD operations and a waitForTask function.
One key part to highlight here is pagination.
MeiliSearch supports two types of pagination:
- offset and limit
- page and hitsPerPage
In our case, we chose to use the page and hitsPerPage style.
By default, MeiliSearch returns a Searchable result, which serves as the parent type.
However, when using page and hitsPerPage pagination, it returns a SearchResultPaginated.
In our implementation, we used the instanceof check to distinguish between the two and return the correct type accordingly.
For more details, refer to the official documentation.
The next important part to take a closer look at is the waitForTask function.
This function is mainly used during the migration process.
In my case, we already had a lot of data in the database, so I needed to migrate all of it at once.
I’ll explain this part in more detail later.
Handler
This is an example, as follows:
public void addPost(GuildPost post, Long userIdx) {
UserInfo userInfo = userService.findByUserIdx(userIdx);
guildService.addPost(post);
SearchDocument searchDocument = createSearchDocument(post, userInfo);
try {
TaskInfo result = meiliSearchService.addOrUpdateDocument(searchDocument);
log.info("Post guild-{} added to search index successfully with task {}", post.getPostIdx(), result.getTaskUid());
} catch (Exception e) {
log.error("Failed to add post guild-{} to search index: {}", post.getPostIdx(), e.getMessage());
}
}
public void updatePost(GuildPost post, Long userIdx) {
UserInfo userInfo = userService.findByUserIdx(userIdx);
guildService.updatePost(post, userIdx);
SearchDocument searchDocument = createSearchDocument(post, userInfo);
try {
TaskInfo result = meiliSearchService.addOrUpdateDocument(searchDocument);
log.info("Post guild-{} updated in search index successfully with task {}", post.getPostIdx(), result.getTaskUid());
} catch (Exception e) {
log.error("Failed to update post guild-{} in search index: {}", post.getPostIdx(), e.getMessage());
}
}
public void removePost(long postIdx, long userIdx) {
guildService.removePost(postIdx, userIdx);
try {
TaskInfo result = meiliSearchService.deleteDocument("guild-" + postIdx);
log.info("Post guild-{} removed from search index successfully with task {}", postIdx, result.getTaskUid());
} catch (Exception e) {
log.error("Failed to remove post guild-{} from search index: {}", postIdx, e.getMessage());
}
}
private SearchDocument createSearchDocument(GuildPost post, UserInfo userInfo) {
GuildDocumentDto guildDocumentDto = GuildDocumentDto.fromDomain(post, userInfo);
return SearchDocument
.builder()
.id("guild-" + post.getPostIdx())
.type("guild")
.title(post.getPostTitle() != null ? post.getPostTitle() : "")
.description(guildDocumentDto.toDescription())
.url("/guild/" + post.getPostIdx())
.createdAt(LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm")))
.build();
}Here, we included only the essential functions. you can safely remove the logging parts.
We added logging temporarily to verify that everything works correctly, but we plan to remove these logs during refactoring.
To summarize, Title and Description are used as the searchable data, and we use filters to search within specific types.
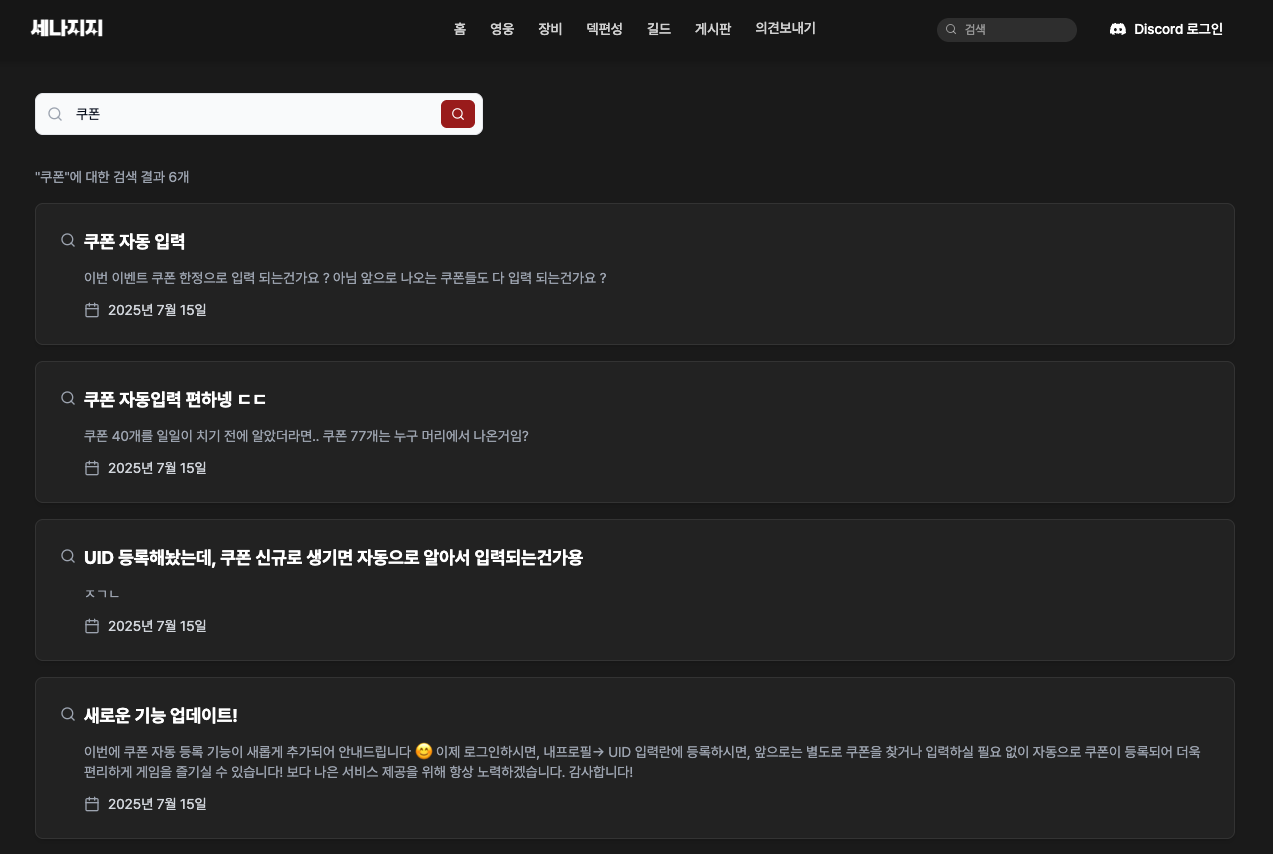
Migration
If you didn’t use MeiliSearch from the beginning, you will likely need to perform a migration.
I implemented a dedicated service to handle the migration process.
MigrationService
@Service
@RequiredArgsConstructor
@Slf4j
@ConditionalOnProperty(name = "migration.guild.enabled", havingValue = "true")
public class GuildMigrationService implements CommandLineRunner {
private final GuildService guildService;
private final GuildHandler guildHandler;
private final UserService userService;
private static final int BATCH_SIZE = 50;
private final MeiliSearchService meiliSearchService;
@Override
public void run(String... args) throws Exception {
log.info("Starting guild migration to MeiliSearch...");
try {
migrateGuildPosts();
log.info("Guild migration completed successfully");
} catch (Exception e) {
log.error("Guild migration failed: {}", e.getMessage(), e);
throw e;
}
}
private void migrateGuildPosts() throws InterruptedException {
log.info("Remove all Guild data from MeiliSearch...");
TaskInfo taskInfo = meiliSearchService.removeByType("guild");
meiliSearchService.waitForTask(taskInfo);
log.info("Fetching all guild posts from database...");
int page = 1;
int totalMigrated = 0;
while (true) {
List<GuildPost> posts = guildService.findAllPosts(BATCH_SIZE, page);
if (posts.isEmpty()) {
break;
}
log.info("Processing batch {} with {} guild posts", page, posts.size());
for (GuildPost post : posts) {
try {
UserInfo userInfo = userService.findByUserIdx(post.getUserIdx());
guildHandler.addGuildPostToSearchIndex(post, userInfo);
totalMigrated++;
if (totalMigrated % 10 == 0) {
log.info("Migrated {} guild posts so far...", totalMigrated);
}
} catch (Exception e) {
log.error("Failed to migrate guild post {} ({}): {}",
post.getPostIdx(), post.getPostTitle(), e.getMessage());
}
}
page++;
}
log.info("Migration completed. Total guild posts migrated: {}", totalMigrated);
}
}The removeType function deletes all data of the specified type, but since the deletion is not immediate, we use the previously mentioned waitForTask(taskInfo) to wait until the deletion is fully completed before proceeding with the creation process.
Next, you should pay attention to the @ConditionalOnProperty(name = "migration.guild.enabled", havingValue = "true") annotation.
You need to configure this property in the application.yml file as follows:
migration:
guild:
enabled: falseIf you set enabled to true and start the server, the migration will run automatically.
Test
After implementing the code, I created an integration test to verify that everything works correctly and no errors occur.
@SpringBootTest
@AutoConfigureMockMvc
@Testcontainers
@ActiveProfiles("test")
@Sql(scripts = "/init.sql", executionPhase = Sql.ExecutionPhase.BEFORE_TEST_CLASS)
@Import(IntegratedMockConfig.class)
@Rollback(true)
class GuildControllerIntegrationTest {
@Autowired
private MockMvc mockMvc;
@Autowired
private MeiliSearchService meiliSearchService;
@Autowired
private UserService userService;
@Autowired
private GuildRepository guildRepository;
@Autowired
private ObjectMapper objectMapper;
@Autowired
private JwtUtil jwtUtil;
@Autowired
private Client meiliClient;
@Container
static GenericContainer<?> meilisearchContainer = new GenericContainer<>(
DockerImageName.parse("getmeili/meilisearch:v1.15"))
.withExposedPorts(7700)
.withEnv("MEILI_MASTER_KEY", "test-master-key")
.withEnv("MEILI_ENV", "development")
.withStartupTimeout(Duration.ofMinutes(2));
@DynamicPropertySource
static void configureProperties(DynamicPropertyRegistry registry) {
if (!meilisearchContainer.isRunning()) {
meilisearchContainer.start();
}
String meilisearchUrl = "http://localhost:" + meilisearchContainer.getMappedPort(7700);
registry.add("meilisearch.host", () -> meilisearchUrl);
registry.add("meilisearch.apiKey", () -> "test-master-key");
}
@BeforeEach()
void setUp() {
meiliClient.createIndex("contents", "id");
meiliClient.index("contents").updateFilterableAttributesSettings(new String[]{"type"});
meiliClient.index("contents").updateSearchableAttributesSettings(new String[]{"title", "description"});
}
@Test
void 길드_등록_테스트() throws Exception {
User user = createUser();
GuildPost guildPost = GuildPost.builder()
...
.build();
String json = objectMapper.writeValueAsString(guildPost);
ResultActions result = mockMvc.perform(post("/api/guild")
.contentType(MediaType.APPLICATION_JSON)
.cookie(new Cookie("access_token", <token>))
.content(json));
result.andExpect(status().isCreated());
result.andExpect(jsonPath("$.message").value("Success"));
//DB
...
List<GuildPost> postAll = guildRepository.findPostAll(condition);
assertEquals(1, postAll.size());
assertEquals("New Guild", postAll.getFirst().getPostTitle());
// 동기화 이슈로 인한 대기 필요
Thread.sleep(500);
//MeiliSearch
SearchResultPaginated search = meiliSearchService.search("New Guild", "guild", 1, 10);
System.out.println(search);
assertNotEquals(0, search.getHits().size());
assertEquals(search.getHits().getFirst().get("title"), "New Guild");
}As Code above, I used TestContainers to run MeiliSearch in a temporary Docker container, which allowed me to verify that the tests ran successfully.
Result
After implementing MeiliSearch, we experienced a significant improvement in our search functionality, with noticeably faster response times.
Given our limited memory environment on a VPS, MeiliSearch’s efficient memory usage made it an ideal choice for us.
It also supports Korean language processing, customizable ranking rules, and many other features, all of which met our needs without compromise.
Overall, we are very satisfied with the results.
Share this post
Comments (0)
No comments yet. Be the first to comment!