Handling 2,000 TPS: Payment System (Part 3)
October 3, 2025
In the previous post, I converted the system to asynchronous processing so that all requests could be handled without being dropped.
However, I noticed that the consumers were taking an extremely long time to complete their work.
The reason was that even with 500 connections and partitions, the database connection pool was limited to 100, forcing consumers to wait.
Based on this observation, I ran the next test by increasing the connection pool to 500.
Increasing the Connection Pool
Postgres has a default limit of 100 connections, so even if you set the value to 500 in the properties, it will not increase unless the max_connections setting is explicitly configured in the database.
Reference) docs.postgres.org
Therefore, I updated the configuration in PostgreSQL.
Referring to Stackoverflow, I applied changes not only to max_connections, but also to shared_buffers and shm_size. (In a production environment, it’s generally more efficient to use PgBouncer.)
The shared_buffers parameter is the memory allocated for caching, and it is typically recommended to set it to about 25% of the system memory. Since I was considering future sharding, I set it to 2GB.
The shm_size parameter defines the amount of shared memory available to the Docker container. As cache memory increases, shm_size must also be increased. If shm_size is set too low, the Docker container may fail to start properly.
Code
services:
postgres:
...
shm_size: '3gb'
command: [ "postgres", "-c", "max_connections=500", "-c", "shared_buffers=2GB" ]I updated the configuration accordingly.

Test TPS 2000
Since smaller TPS values are no longer meaningful, I ran the test directly at 2,000 TPS using k6.
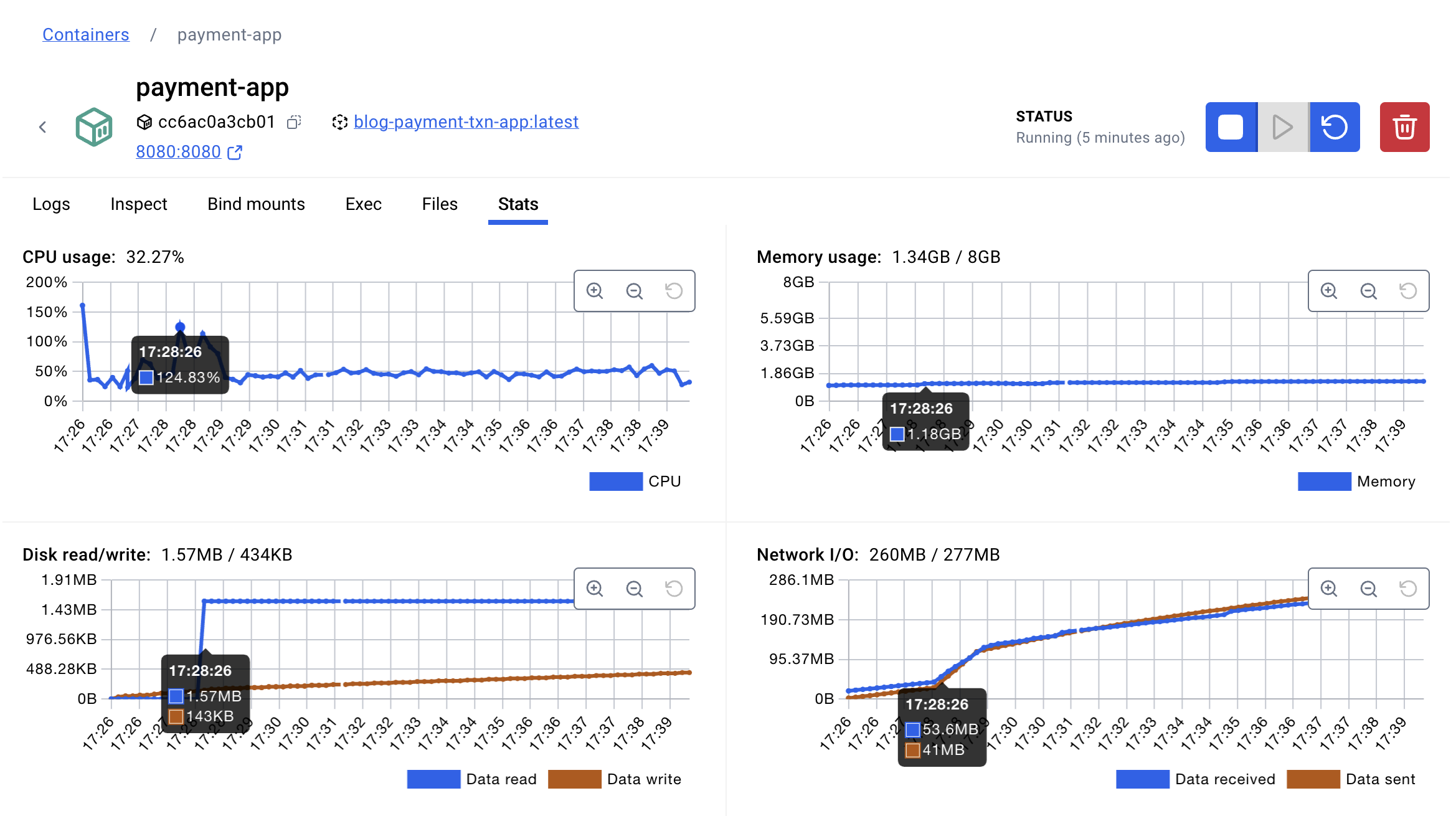

The CPU usage suddenly spiked, but since it did not reach the maximum level, the system still appeared stable.
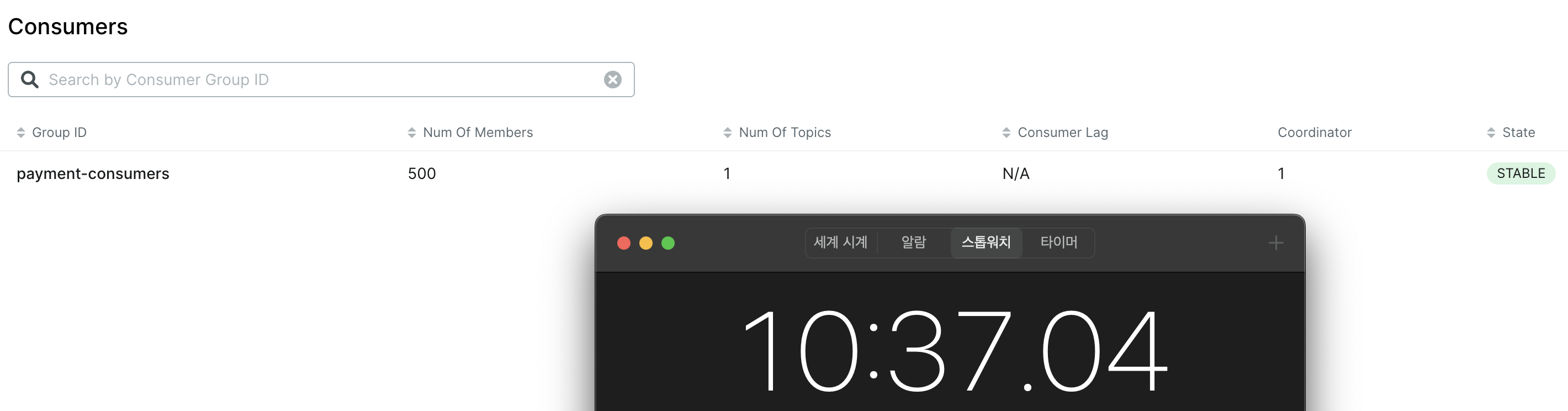
Previously, processing took about 30 minutes, but after increasing the connection pool, it was reduced to around 10 minutes.
However, since I expected it to finish in about 5 minutes, the actual result revealed a performance bottleneck.
In other words, simply increasing the connection pool was not enough. A single database has inherent limitations in transaction processing, locking, and disk I/O. To achieve the target of under 30 seconds, architectural improvements such as sharding are essential.
Sharding
Initially, I experimented with Citus for sharding, but the Coordinator node became a bottleneck.
As a result, I moved to application level sharding.
The key logic of this approach is shown below.
private static final ThreadLocal<String> contextHolder = new ThreadLocal<>();
public static void setShardKey(Long userId, int shardCount) {
int shardId = (int)(userId % shardCount);
contextHolder.set("db" + shardId);
}
@Override
protected Object determineCurrentLookupKey() {
return contextHolder.get();
}When a thread accesses the repository, it uses setShardKey to set the shard and then routes the query to the corresponding database.
For transactions, I used a combination of 5 shard databases + 1 global database, for a total of 6 databases.
The full code is available at: https://github.com/pkt369/blog-payment-txn/tree/v3.
Test
For better results, I increased the setup to 1,500 partitions and 1,500 consumers, and ran the test with 6 databases.

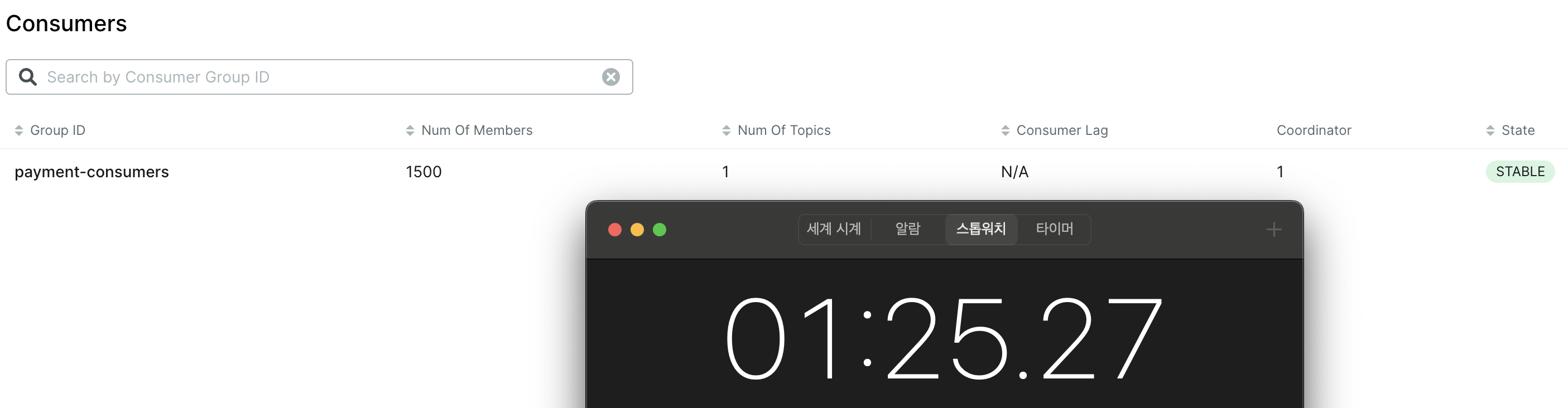
The entire process took 1 minute and 25 seconds, which means that the final request took about 25 seconds to complete.
Compared to the previous tests where some requests took more than 10 minutes, reducing it to 25 seconds was a significant improvement.
However, due to the limitations of the local environment, it was not possible to reduce the time to just a few seconds.
In particular, round robin balancing did not work evenly, causing load to concentrate on certain consumers and resulting in lag (message backlog).
Additionally, CPU usage exceeded the available cores, leading to context switching overhead, GC delays, and Disk I/O contention, which further slowed processing.
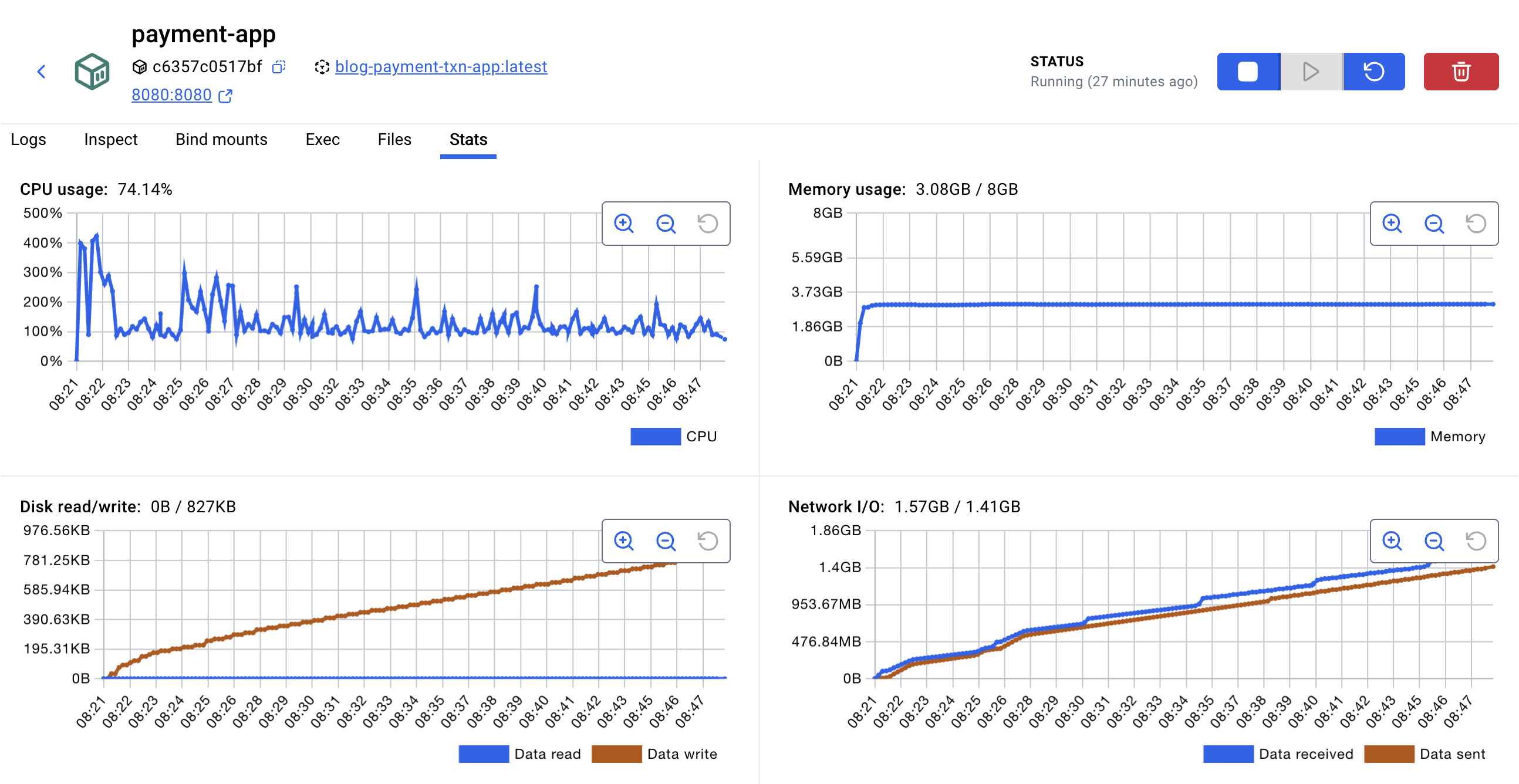
In other words, distributing consumer load and expanding resources are essential to further reduce processing time.
In a production environment, these constraints would be alleviated, making it possible to achieve payment speeds within just a few seconds.
Summary
Through this test, I confirmed that insufficient physical resources can lead to slower processing speeds.
By expanding the database connection pool, I was able to improve consumer throughput, and by applying sharding to overcome the limitations of a single database, I successfully achieved the target of processing within 30 seconds.
Due to the constraints of the local environment, the performance was naturally slower, but in a production setting, I expect much better results.
Conclusion
This post marks the end of the Payment System series, but there are still limitations before it can be applied in a real production environment.
For example, while introducing application level sharding, read performance degradation occurred. This issue could be addressed by adopting a NoSQL solution optimized for read heavy traffic, or by applying a CQRS pattern to separate read and write responsibilities.
Share this post
Comments (0)
No comments yet. Be the first to comment!