Handling 2,000 TPS: Payment System (Part 2)
August 27, 2025
Finding Improvements
In the previous post, we looked at how to test and identified the TPS limitations.
In this post, we’ll explore how to address bottlenecks and overcome those limitations.
According to the previous post, we saw that the rate of incoming requests was much higher than the server could process.
Of course, we could configure the Hikari connection pool in Spring Boot with more than 100 connections, but for learning purposes it was limited to 100.
We plan to increase the number of connections later.
In the last post, we also observed the limitations of a synchronous processing system, and now we will gradually address them through system architecture design.
The future architecture looks like this.
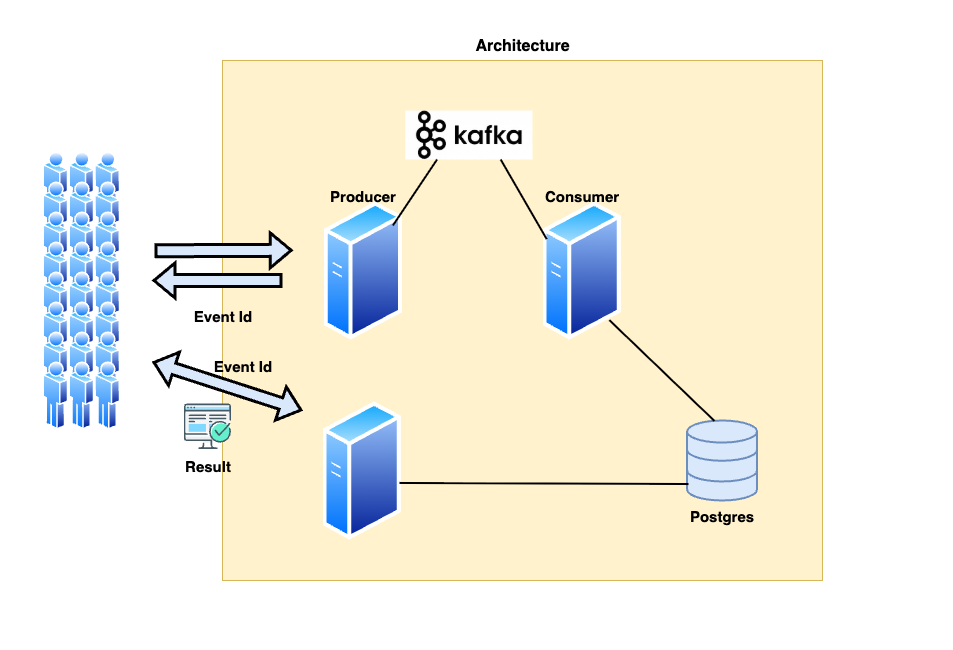
As the first step, we will introduce asynchronous processing.
The biggest reason the system fails to handle TPS is that the connection pool cannot keep up with the requests, causing bottlenecks. By applying asynchronous processing, we gain two benefits:
- We can increase the TPS capacity through scale-out.
Q: Isn’t scale-out possible without asynchronous processing?
A: Yes, that’s true. However, when TPS spikes during peak time, the same issue will occur.
The most important goal right now is to ensure that payment requests are processed reliably without being dropped. Therefore, reducing response time as much as possible is our key objective.
- Even if payment processing takes a bit longer, requests will not be dropped.
Asynchronous (Kafka)
To enable asynchronous processing, we will introduce a message queue system.
I chose Kafka instead of RabbitMQ for the following reasons:
- Kafka persists messages to disk and supports parallel processing through partitions. This makes it suitable for large-scale TPS handling and replayability.
- RabbitMQ, on the other hand, can create multiple queues but has limited official support for massive TPS and partition-based parallel processing.
For Kafka, I used the Bitnami Kafka distribution.
Reference: docker-compose.yml
Since this is a local environment, I used the PLAINTEXT protocol. To prevent duplicate message delivery, I enabled the option enable.idempotence=true.
Additionally, I set consumer.max-poll-records=10 and configured a 1-minute timeout to prevent consumers from being killed.
We need to separate the system into two components:
- A Producer server that receives payment requests and publishes messages to Kafka.
- A Consumer server that reads messages from Kafka and processes the actual payment.
In a production environment, these should be deployed separately, but for testing purposes, I implemented both within a single server.
Initially, I configured three Kafka partitions and scaled up as needed during testing.
Code
java// Producer public void publish(TransactionEvent event) { CompletableFuture<SendResult<String, TransactionEvent>> future = kafkaTemplate.send(topic, event); future.whenComplete((res, ex) -> { if (ex != null) { System.err.println("Kafka publish failed: " + ex.getMessage()); } }); } // Service public String createTransaction(TransactionRequest request) { TransactionEvent pending = TransactionEvent.builder() .eventId(UUID.randomUUID().toString()) .userId(request.getUserId()) .amount(request.getAmount()) .type(request.getType()) .status(TransactionStatus.PENDING) .createdAt(LocalDateTime.now()) .build(); producer.publish(pending); return pending.getEventId(); }
The system receives an event object and sends it to Kafka partitions using a round-robin approach. After sending, it returns the Event ID, which users can use to check the processing status via polling.
Additionally, the main logic of the existing service has been moved to the consumer.
The complete code is available on the Git Repository.
TPS Test



The TPS values tested above were 100, 1,000, and 2,000, respectively.
When the system operated synchronously, the average response time was 1.52 seconds, and the TPS achieved was 95.6.
After converting to an asynchronous processing approach, the average response time across the three tests dropped to 0.96 ms, an improvement of roughly 1,583x.
Even at the target TPS of 2,000, we observed that all requests were successfully processed without any drops.
However, a problem arose. The consumer was processing too slowly.
The processing speed directly affects how long users have to wait for their payment to complete, making it a critical factor.
- Total transactions per consumer: 120,000 ÷ 3 = 40,000
- Processing time: 40,000 x 1s = 40,000s => 11 hours and 6 minutes
This highlighted the need for further optimization in consumer throughput.
Consumer
Although dropped requests were resolved, we observed that users still had to wait a long time for their payments to complete.
The reason was that messages were not being consumed quickly enough. To address this, we plan to increase both the number of consumers and partitions.
Previously, we were processing with 3 consumers and 3 partitions.
To complete payments within 5 seconds, the required throughput would be: 120,000 ÷ 5 seconds = 24,000 TPS.
This meaning 24,000 events need to be processed simultaneously.
Due to the limitations of the local environment, we will start by increasing the number of consumers to 500.
(With 500 consumers, the estimated processing time is roughly 4 minutes.)
500 Consumers Test

We successfully processed all 120,000 messages, and the server’s stability improved compared to the synchronous approach!
However, although we expected it to take 4 minutes, it actually took nearly 30 minutes.
This was because increasing consumers and partitions did not increase the Hikari connection pool (database pool).
In the next series, we plan to increase the database pool to improve consumer throughput and achieve faster responses.
Troble Shooting
TPS 2,000 + Consumer 500
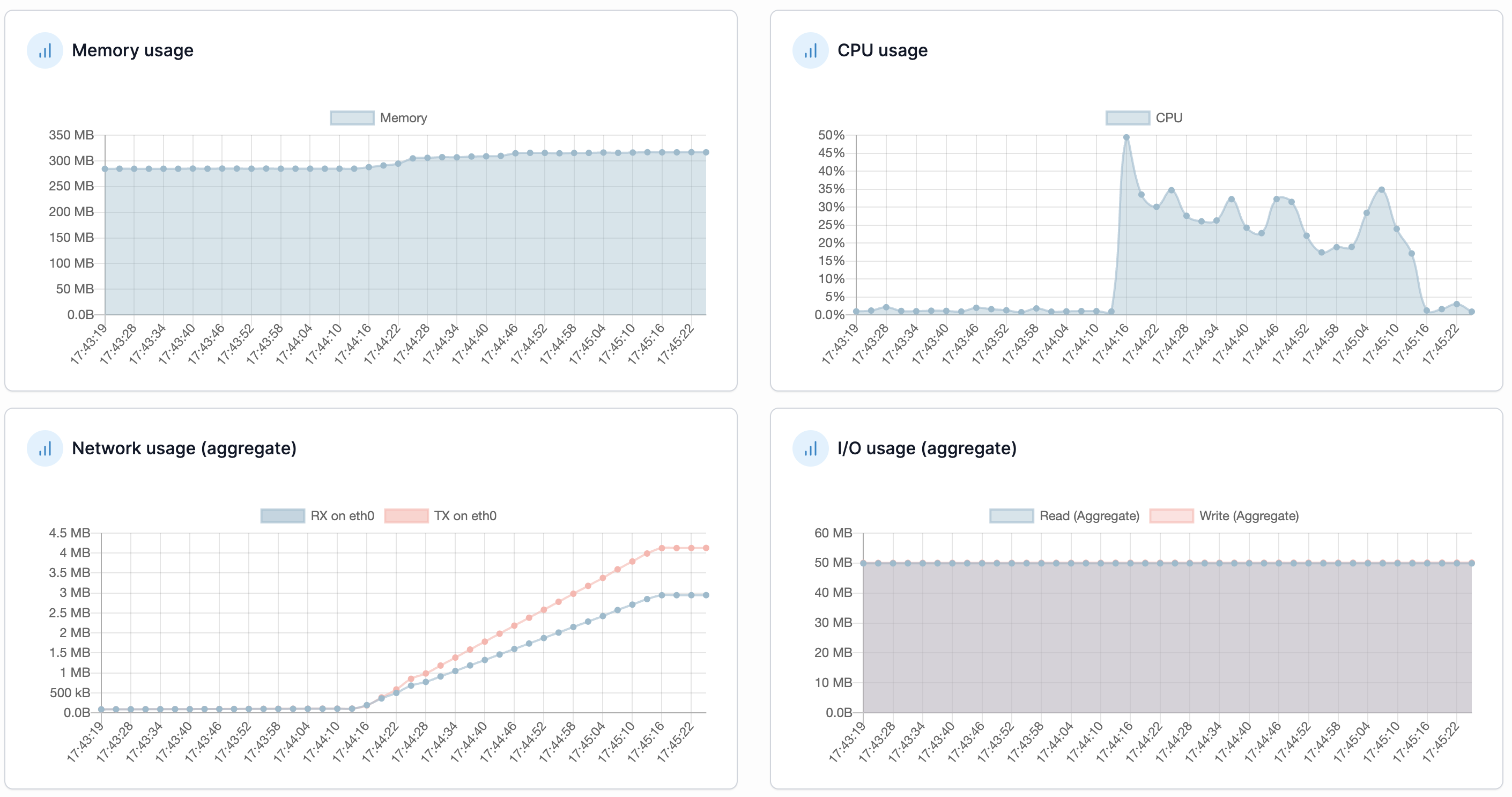
We ran a test at TPS 2,000, and the results are shown in the figure below.

During the test, the number of active consumers dropped to 0 out of 27,806 messages, triggering a rebalancing state and preventing further reduction.
Checking the logs, I found.
Member Consumer sending LeaveGroup request to coordinator kafka:9092 (id: 2147483646 rack: null) due to consumer poll timeout has expired.
The root cause was:
- max-poll-records was set to 500
- request.timeout.ms was 30,000 ms (30 seconds)
In other words, if a consumer fails to process 500 messages within 30 seconds, the producer marks the request as failed, and the broker considers the consumer dead and removes it from the group.
This explains why, as shown in the figure, the number of active consumers dropped to zero.
To address this issue, we applied two solutions:
- Reduce the number of messages polled at a time (max-poll-records)
- Increase request.timeout.ms
Both solutions were applied successfully, preventing consumers from being removed prematurely.
Share this post
Comments (0)
No comments yet. Be the first to comment!